java의 jsoup 라이브러리를 이용해 서울시 공공서비스 예약 사이트(https://yeyak.seoul.go.kr)에서 테니스장 게시글의 제목과 장소 정보를 크롤링해보겠습니다.
아래의 사진을 보시면 총 131개의 테니스장 게시글이 존재하고 페이지당 6개씩 게시글로 이루어짐을 볼 수 있습니다.

가장 먼저 build.gradle의 dependencies에 jsoup을 추가합니다.
implementation 'org.jsoup:jsoup:1.14.3'
다음으로 테니스장 정보를 담는 클래스를 만들어 보겠습니다.
간단하게 public으로 도배하고 출력 시 참조값이 아닌 필드 값이 나오도록 toString을 오버라이드 하였습니다.
public class Tennis {
public String title;
public String location;
public Tennis(String title, String location) {
this.title = title;
this.location = location;
}
@Override
public String toString() {
return "Tennis{" +
"title='" + title + '\'' +
", location='" + location + '\'' +
'}';
}
}
이제 크롤링할 페이지 url을 분석해야 합니다.
테니스장의 게시글을 보여주는 url은
https://yeyak.seoul.go.kr/web/search/selectPageListDetailSearchImg.do?code=T100&dCode=T108 입니다.
축구장의 목록의 url은 파라미터가 code=T100&dCode=T107이고, 농구장은 code=T100&dCode=T101 인 것을 확인했는데요.
code와 dCode라는 파라미터로 특정 운동장을 나타내고 있습니다.
저희는 테니스장만 필요하니 code=T100&dCode=T108 만 기억하면 되겠습니다.
추가로 테니스 리스트가 페이징 처리가 되어 있기 때문에 페이징에 관련된 파라미터도 봐야 됩니다.
https://yeyak.seoul.go.kr/web/search/selectPageListDetailSearchImg.do?currentPage=2
2페이지를 넘어가 보니 currentPage=2라는 파라미터가 추가되었네요. currentPage로 페이징을 구현하고 있습니다.
지금까지 url을 분석해 SeoulTennisCrawler라는 클래스를 만들어 지금까지의 내용을 코드로 작성해봤습니다.
public class SeoulTennisCrawler {
private final String MAIN_URL = "https://yeyak.seoul.go.kr/web/search/selectPageListDetailSearchImg.do";
private final String TENNIS_CODE = "code=T100&dCode=T108";
private final String PAGE = "currentPage=";
public String getTennisUrl(int page) {
return MAIN_URL + "?" + TENNIS_CODE + "&" + PAGE + page;
}
}getTennisUrl() 메서드를 통해 url을 반환하도록 만들어 보았습니다.
아래는 간단히 테스트 코드를 작성해보았습니다.
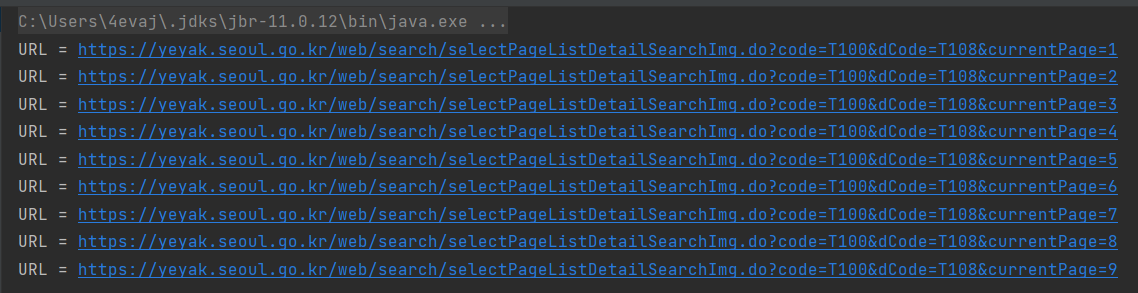
테스트 코드 결과 URL을 잘 만들어 주네요. 클릭 시 정상적으로 페이지가 호출됨을 확인했습니다.
class SeoulTennisCrawlerTest {
SeoulTennisCrawler crawler = new SeoulTennisCrawler();
@Test
public void getTennisUrl() {
for (int i = 1; i < 10; i++) {
System.out.println("URL = " + crawler.getTennisUrl(i));
}
}
}
이제 페이지의 html 코드를 분석해야 합니다.
jsoup 크롤링은 html 코드를 불러와 태그나 클래스명을 통해 원하는 element를 가져오는 방식이기 때문입니다.
브라우저에서 f12를 클릭하면 html 코드를 볼 수 있습니다.
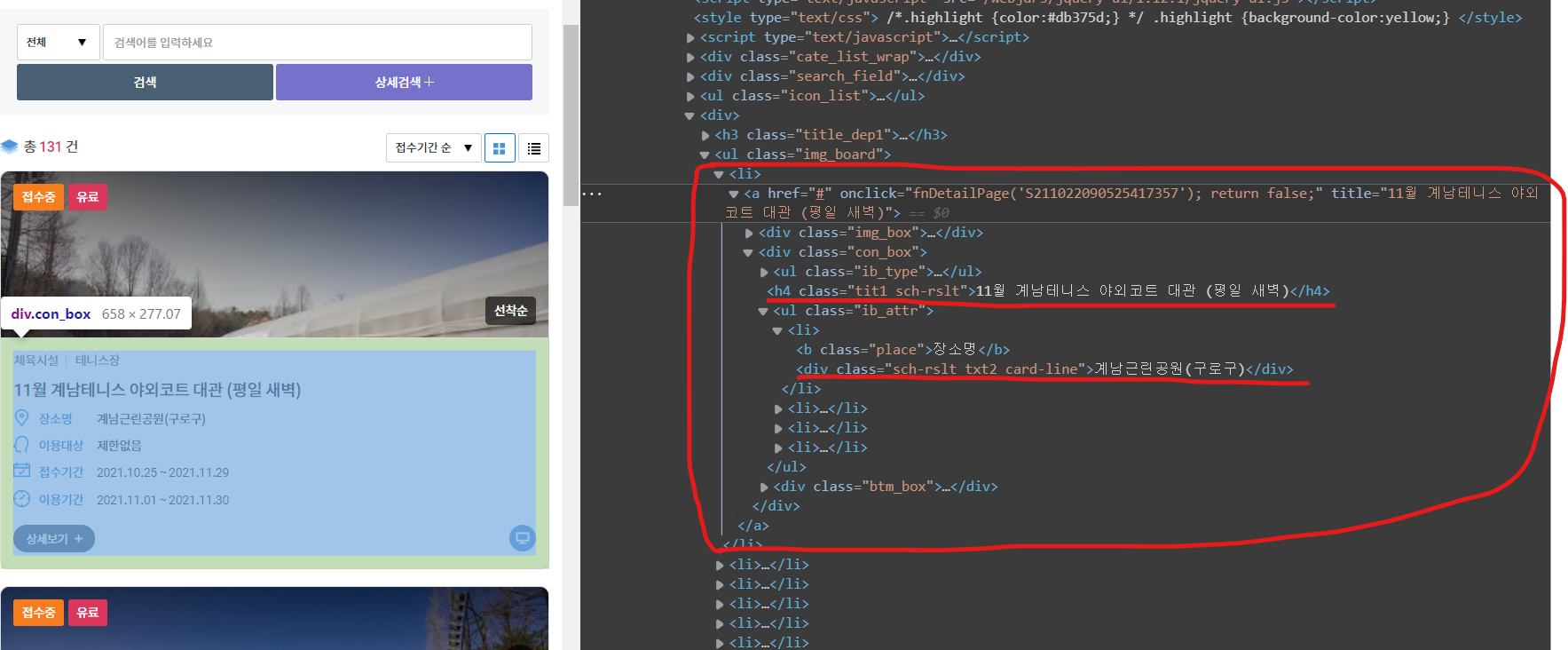
저희가 주의 깊게 봐야 할 부분은 <ul class="img_board">의 <li> 태그입니다.
<li> 자식 태그 중에 <h4 class="tit1 sch-rslt">이 게시글의 제목이고 <div class="sch-rslt txt2 card-line">가 테니스장의 장소입니다.
이제 본격적으로 jsoup을 사용해 데이터를 뽑아 보겠습니다.
public List<Tennis> getTennisData(String tennis_url) throws IOException {
List<Tennis> tempList = new ArrayList<>();
// 전체 html 코드
Document document = Jsoup.connect(tennis_url).get();
// 제목을 가지고 있는 요소 반환
// <ul class="img_board"> -> ul.img_board
// <h4 class="tit1 sch-rslt"> -> h4.tit1.sch-rslt
Elements titleElements = document.select("ul.img_board h4.tit1.sch-rslt");
// <div class="sch-rslt txt2 card-line"> -> div.sch-rslt.txt2.card-line
Elements locationElements = document.select("ul.img_board div.sch-rslt.txt2.card-line");
for (int i = 0; i < titleElements.size(); i++) {
// titleElements text 추출
String title = titleElements.get(i).text();
// locationElements text 추출
String location = locationElements.get(i).text();
Tennis tennis = new Tennis(title, location);
tempList.add(tennis);
}
return tempList;
}좀 전에 만든 getTennisUrl() 메서드를 통해 만든 url을 가지고 Jsoup.connect(tennis_url). get() 호출을 하게 되면 html 코드의 내용을 가지고 있는 Document라는 객체를 반환하게 됩니다.
다음 Document 객체의 select() 메서드를 통해 원하는 elements를 가져올 수 있습니다. select() 메서드엔 가져오고 싶은 element의 태그나 클래스명을 넣어주면 되는데 "태그명. 클래스명. 클래스명" 형식으로 만들면 됩니다. 자세한 내용은 코드를 확인해 주세요.
이제 각각 titleElements와 locationElements를 가져왔고 반복문을 통해 text 값을 추출해 Tennis 객체를 만들고 List에 담도록 하였습니다.
아래는 테스트 코드입니다.
정상적으로 첫 번째 페이지에 있는 게시글들을 크롤링했습니다.
@Test
public void getTennisData() throws IOException {
String tennisUrl = crawler.getTennisUrl(1);
List<Tennis> tennisData = crawler.getTennisData(tennisUrl);
for (Tennis tennis : tennisData) {
System.out.println(tennis.title + " / " + tennis.location);
}
}
이제 본격적으로 크롤링을 해보겠습니다.
무한 반복문에 위에서 만든 getTennisData() 메서드를 호출해 allTennis라는 리스트에 저장을 합니다. 더 이상 getTennisData() 메서드에서 테니스 데이터를 가져오지 못한다면 break로 반복문을 빠져나오게 만들었습니다.
public List<Tennis> crawling() throws IOException {
List<Tennis> allTennis = new ArrayList<>();
int page = 1;
while (true) {
String tennisUrl = getTennisUrl(page++);
List<Tennis> tennisData = getTennisData(tennisUrl);
if (tennisData.size() == 0) break;
allTennis.addAll(tennisData);
}
return allTennis;
}테스트 코드입니다.
총 131개의 테니스장 게시글을 정상적으로 크롤링을 하였습니다.
@Test
public void crawling() throws IOException {
crawler.crawling();
for (Tennis tennis : SeoulTennisCrawler.tennis) {
System.out.println(tennis);
}
Assertions.assertEquals(SeoulTennisCrawler.tennis.size(), 131);
}
전체 코드
Tennis.class
package crawler;
public class Tennis {
public String title;
public String location;
public Tennis(String title, String location) {
this.title = title;
this.location = location;
}
@Override
public String toString() {
return "Tennis{" +
"title='" + title + '\'' +
", location='" + location + '\'' +
'}';
}
}
SeoulTennisCrawler.class
package crawler;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class SeoulTennisCrawler {
private final String MAIN_URL = "https://yeyak.seoul.go.kr/web/search/selectPageListDetailSearchImg.do";
private final String TENNIS_CODE = "code=T100&dCode=T108";
private final String PAGE = "currentPage=";
public String getTennisUrl(int page) {
return MAIN_URL + "?" + TENNIS_CODE + "&" + PAGE + page;
}
public List<Tennis> getTennisData(String tennis_url) throws IOException {
List<Tennis> tempList = new ArrayList<>();
// 전체 html 코드
Document document = Jsoup.connect(tennis_url).get();
// 제목을 가지고 있는 요소 반환
// <ul class="img_board"> -> ul.img_board
// <h4 class="tit1 sch-rslt"> -> h4.tit1.sch-rslt
Elements titleElements = document.select("ul.img_board h4.tit1.sch-rslt");
// <div class="sch-rslt txt2 card-line"> -> div.sch-rslt.txt2.card-line
Elements locationElements = document.select("ul.img_board div.sch-rslt.txt2.card-line");
for (int i = 0; i < titleElements.size(); i++) {
// titleElements text 추출
String title = titleElements.get(i).text();
// locationElements text 추출
String location = locationElements.get(i).text();
Tennis tennis = new Tennis(title, location);
tempList.add(tennis);
}
return tempList;
}
public List<Tennis> crawling() throws IOException {
List<Tennis> allTennis = new ArrayList<>();
int page = 1;
while (true) {
String tennisUrl = getTennisUrl(page++);
List<Tennis> tennisData = getTennisData(tennisUrl);
if (tennisData.size() == 0) break;
allTennis.addAll(tennisData);
}
return allTennis;
}
}
SeoulTennisCrawlerTest.class
package crawler;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
import java.io.IOException;
import java.util.List;
import static org.junit.jupiter.api.Assertions.*;
class SeoulTennisCrawlerTest {
SeoulTennisCrawler crawler = new SeoulTennisCrawler();
@Test
public void getTennisUrl() {
for (int i = 1; i < 10; i++) {
System.out.println("URL = " + crawler.getTennisUrl(i));
}
}
@Test
public void getTennisData() throws IOException {
String tennisUrl = crawler.getTennisUrl(1);
List<Tennis> tennisData = crawler.getTennisData(tennisUrl);
for (Tennis tennis : tennisData) {
System.out.println(tennis.title + " / " + tennis.location);
}
}
@Test
public void crawling() throws IOException {
List<Tennis> tennisList = crawler.crawling();
for (Tennis tennis : tennisList) {
System.out.println(tennis);
}
Assertions.assertEquals(tennisList.size(), 131);
}
}'project > Tennis Together' 카테고리의 다른 글
| Tennis Together 5주차 (4) | 2021.11.14 |
|---|---|
| Tennis Together 4주차 (0) | 2021.11.07 |
| Tennis Together 3주차 (0) | 2021.10.30 |
| Tennis Together 2주차 (0) | 2021.10.26 |
| Tennis Together 1주차 (0) | 2021.10.23 |

댓글